

Wielowątkowość to ważne zagadnienie w programowaniu aplikacji w Java. Z tego artykułu dowiesz się, czym są wątki i poznasz mechanizmy związane z obsługą wątków. To pierwszy artykuł z cyklu wielowątkowości w Java, będący teoretycznym wstępem do tematu.
Czym jest wielowątkowość?
W skrócie można powiedzieć, że wielowątkowość to zdolność do współbieżnego wykonywania niezależnych zadań w programie. Program może uruchomić wiele wątków, których działanie będzie zarządzane przez system.
Przykładowo, jeden wątek może zajmować się zapisywaniem pliku, podczas gdy drugi w tym samym czasie wypisuje komunikaty na ekranie.
Nazwa „wątek” nie jest całkowicie przypadkowa. Podobnie do wątków w rozmowach, czy w powieści, wątki w systemie mogą się „przeplatać” i mogą być wykonywane w tym samym czasie. Nie muszą też mieć ze sobą dużo wspólnego, ponieważ w każdym wątku może dziać się coś innego. W programowaniu pojęcie „wątek” zostało wybrane jako pewnego rodzaju analogia do tego, z czym spotykamy się na co dzień.
Wątek jest sposobem podziału procesu na podprocesy, które mogą być przez system wykonywane współbieżnie. Wątki działają podobnie jak nowe procesy uruchomione w systemie, tylko działają „pod kloszem” głównego programu.
Współbieżność to cecha, która oznacza zdolność do występowania kilku zdarzeń niezależnie, w tym samym czasie lub w innym czasie. Wątki są współbieżne, co oznacza, że mogą być wykonywane całkowicie równolegle, ale mogą też być wykonane jeden po drugim – w zależności od tego, czy pozwolą na to dostępne zasoby.
Nie zakładaj, że wszystkie wątki (lub współbieżne zadania) działają w tym samym momencie (równolegle). Nie zakładaj również, że działają w innym czasie. Wątki są niedeterministyczne – nie ma gwarancji co do kolejności wykonywania wątków i kiedy zostaną uruchomione.

Wielowątkowość – zderzenie z rzeczywistością (Źródło)
Co charakteryzuje wątki w Javie?
Wątki w Javie są podobne do wątków każdego innego programu (także napisanego w innym języku). Z tego powodu opiszę wątki jako ogólny mechanizm – dzięki temu będę w stanie przekazać więcej informacji o nich.
Każdy wątek ma swój stos
Aplikacje napisane w Javie wykorzystują pamięć RAM do przechowywania danych na stercie (ang. heap) oraz na stosie (ang. stack).
Instancje klas (obiekty) są przechowywane na stercie, a lokalne zmienne typów prostych, metody, czy referencje do obiektów są przechowywane na stosie. Przykładowo, jeśli zadeklarujesz zmienną typu prostego w metodzie, to patrząc pod kątem przechowywania w pamięci będzie na stosie. Analogicznie, jeśli w metodzie stworzysz nowy obiekt, to referencja do niego będzie na stosie, a sama instancja na stercie.
Jeśli wywołujesz metodę, to wtedy odkłada się ona na stos wywołań – na wierzchu zawsze znajduje się aktualnie uruchomiona metoda. Pod koniec wykonania metody słowo kluczowe „return” zdejmuje metodę ze stosu – powrót do metody wywołującej (ang. caller method).
Stosy nie są współdzielone – każdy wątek samodzielnie śledzi wywołania metod w odrębnych stosach, a także każdy wątek ma swój stos ze zmiennymi lokalnymi.
Wątki jednej aplikacji współdzielą pamięć
Pomimo tego, że każdy wątek posiada swój stos, to nie posiada całkowicie niezależnej pamięci. To jest jedna z cech, która odróżnia wątek od procesu. Sterta jest współdzielona przez cały program – oznacza to, że wątek może odczytywać i modyfikować instancje klas stworzone przez inne wątki. Jest to jeden ze sposobów na „komunikację” wątków w celu przekazania sobie danych.
Warto pamiętać, że dostęp do współdzielonej pamięci ma swoje konsekwencje. Niekontrolowane zmiany współdzielonej pamięci mogą wpływać negatywnie na to, co dzieje się w tym samym czasie w innym wątku. Nie zawsze jesteśmy w stanie przewidzieć, czy w momencie zmiany pamięci nie spowodujemy niepoprawnego wykonania zadania w innym wątku. Istnieją różne mechanizmy (np. synchronizacja), które pozwalają uniknąć takich problemów.
System operacyjny wie, czym jest wątek
Wątki są pewnego rodzaju podprocesami, ale działającymi w ramach jednego programu. W zależności od systemu operacyjnego, wątki działają trochę inaczej, ale można o nich ogólnie powiedzieć, że to są tak jakby procesy, które mają wspólny obszar pamięci.
Dzięki temu, że wątki są „widoczne” dla systemu, to możliwa jest inspekcja działających wątków. System wie, jak dużo wątków używa program, a także jakie zasoby są wykorzystywane przez pojedyncze wątki.
System operacyjny jest w stanie ograniczyć maksymalne zasoby przydzielane wątkom, a także maksymalną liczbę wątków. Dodatkowo różne systemy operacyjne mają różne strategie na przydzielanie zasobów nowym wątkom.
Jądro systemu (ang. kernel) kontroluje mechanizm przełączania wątków (ang. context switching), a procesor to realizuje. W zależności od architektury procesora, system operacyjny może obierać różne strategie co do przełączania kontekstu.
Procesor jest „świadomy” istnienia wątków
Wątki są mechanizmem systemowym, a nie charakterystycznym dla JVM, czy bibliotek. Tak naprawdę obsługa wątków zaczyna się niskopoziomowo – procesory mają wbudowane mechanizmy do zarządzania współbieżną pracą. Wątek jest podstawową jednostką utylizacji pracy procesora.
Wątki mają swój kontekst, który jest fragmentem pamięci i który opisuje wątek. W ramach kontekstu przechowywane są m.in. informacje o stanie wątku, identyfikatorze, wyłącznej pamięci wątku, czy wskaźnik do obecnie wykonywanej instrukcji (ang. program counter).
Nowoczesne procesory wielordzeniowe są w stanie wykonywać jednocześnie kilka instrukcji – pozwala to na pełne zrównoleglenie wątków. Przykładowo, w przypadku procesora 8-rdzeniowego i 8 uruchomionych wątków, każdy rdzeń będzie obsługiwał 1 wątek i 1 kontekst.
Zazwyczaj wątków jest więcej niż rdzeni procesora. W takim wypadku procesor nie wykonuje wszystkich wątków jednocześnie, ponieważ nie ma takiej możliwości. Wtedy wątki zaczną się „przeplatać” – jeden rdzeń będzie musiał realizować instrukcje kilku wątków.
Gdy jeden rdzeń zajmuje się kilkoma wątkami, może to robić na kilka różnych sposobów. Na przykład taki rdzeń może dokończyć pracę jednego wątku, zanim zajmie się kolejnym. Najczęściej jednak zajmuje się wątkami naprzemiennie – przełączając się pomiędzy wątkami co kilka instrukcji. Drugie podejście jest o wiele bardziej praktyczne, bo dzięki temu rdzeń nie jest „zablokowany” dopóki nie dokończy pracy.
Aby śledzić to, co się aktualnie dzieje, procesor dokonuje tzw. przełączania kontekstów (albo przełączanie wątków, ang. context switching). Warto zauważyć, że w teorii przełączanie kontekstów jest kosztowną operacją i procesor zazwyczaj wykonuje zadania z większą wydajnością, gdy nie musi tego robić. Istnieją jednak przypadki, gdzie przełączanie wątków daje nam dodatkowy zysk w wydajności.
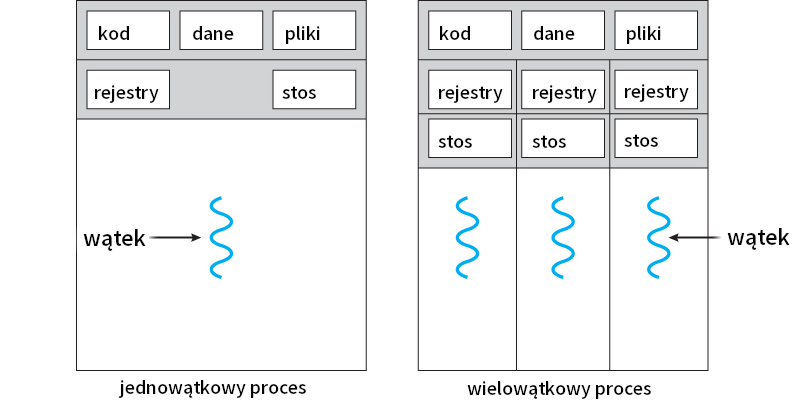
Koncepcyjne porównanie jedno- i wielowątkowego procesu (Źródło: StackOverflow)
Procesor jest wydajniejszy, gdy jest zajęty pracą
Wątki pozwalają na organizację pracy procesora. Dzięki temu procesor jest w stanie podzielić swoją pracę tak, aby zapewnić najszybsze wykonanie zadań. Gdyby ciągi instrukcji nie były podzielone na wątki, to rozdzielenie lub zrównoleglenie pracy byłoby ciężkie, albo nawet niemożliwe.
Często praca w ramach jednego programu (czy procesu biznesowego) jednak nie wymaga takich podziałów. Mogą one wprowadzić niepotrzebne skomplikowanie, a do tego koszt przełączania wątków, synchronizacja danych i niedeterministyczna natura wątków mogą spowodować, że program będzie działał wolniej. Jeśli w programie mamy dużo ciągłej pracy (która byłaby trudna do podziału), to największą wydajność uzyskamy, gdy wątków będzie mniej. Procesor będzie mógł ciągle zajmować się wykonywaniem instrukcji bez niepotrzebnych przestojów.
Program może też wykonywać operacje wejścia/wyjścia, tzw. IO (np. dostęp do dysku, oczekiwanie na pakiet TCP). Te operacje zazwyczaj wymagają od procesora zaczekania. W celu uniknięcia zablokowania rdzeni podczas takiego oczekiwania, procesor chwilowo przestaje zajmować się tym wątkiem i zajmuje się obsługą innych zadań. Są dwie strategie informowania o ukończeniu polecenia IO – pierwsza to przerwanie (ang. interrupt), czyli sygnał wysłany z urządzenia do procesora. Druga to odpytywanie (ang. polling), gdzie procesor cyklicznie sprawdza, czy dane są „gotowe” i wątek może wznowić działanie. Odpytywanie może być wykonywane w międzyczasie i zazwyczaj nie obciąża znacznie procesora.
W przypadku gdy wykonujemy dużo operacji IO w naszym programie – dobrą strategią jest użycie wielu wątków, aby procesor mógł lepiej wykorzystać bezczynność każdego wątku. Natomiast w przypadku długich zadań bez przerw (bez IO) narzut częstego przełączania kontekstu może znacznie opóźnić działanie programu.
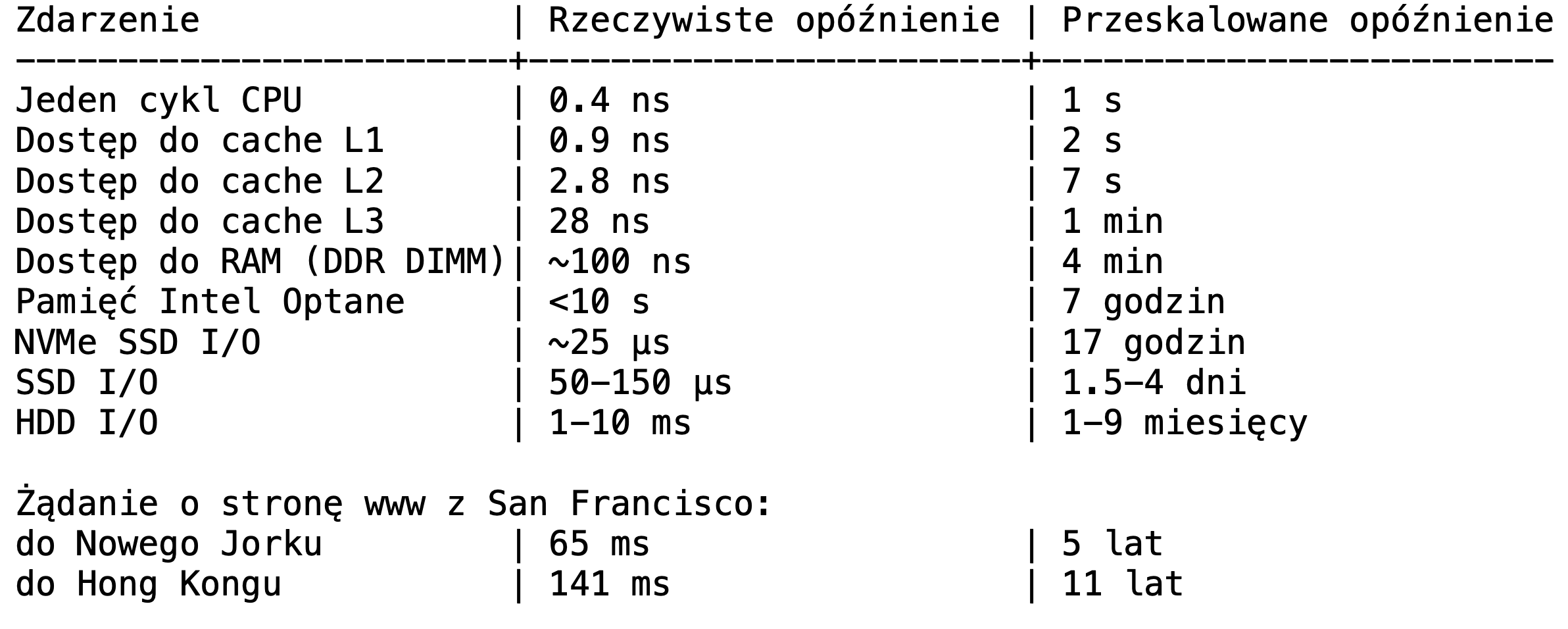
Tabela prezentująca opóźnienie IO przeskalowane do „ludzkich” jednostek czasu
(Źródło: David Jeppesen, Prowess Consulting, na podstawie pracy “Systems Performance: Enterprise and the Cloud” autorstwa Brendana Gregga)
Wątki nie są uruchamiane deterministycznie
W związku z wieloma zmiennymi, które wpływają na to, jak działają wątki i kiedy rzeczywiście działają, powstaje problem z określeniem, kiedy zostaną uruchomione i kiedy zakończą swoje zadanie.
Nie ma gwarancji, że jeden wątek zakończy działanie przed drugim, nawet jeśli został uruchomiony jako pierwszy, albo ma mniej do zrobienia. Może też się zdarzyć, że system opóźni uruchomienie wątku ze względu na mało dostępnych zasobów.
Te wszystkie kwestie trzeba brać pod uwagę przy projektowaniu rozwiązań wielowątkowych. Czasami problemy wynikające z korzystania z wielu wątków mogą utrudnić, albo uniemożliwić implementację programu w sposób współbieżny. Koszty stworzenia nowego wątku, przełączania kontekstów i synchronizacji mogą w końcu spowodować, że rozwiązanie współbieżne będzie działało wolniej.
Co dalej?
W kolejnych artykułach z cyklu opowiem o tym, jak tworzyć wątki i jak nimi zarządzać. Zaprezentuję także praktyczne rozwiązania, które można wykorzystać w aplikacjach wielowątkowych do poprawnego zarządzania pamięcią i zadaniami. Dodatkowo przedstawię typowe problemy, które mogą się pojawić w takich aplikacjach, a także sposoby unikania błędów.
Następny artykuł: Wielowątkowość w Java – tworzenie wątków

