

Cześć. Nazywam się Łukasz Suski i jestem Android Tech Leadem w Finanteq.
O czym dzisiaj opowiem?
W poniższym artykule poruszę temat automatycznych testów UI na platformie Android na dużą skalę.
Dlaczego akurat ten temat jest wart uwagi?
Testy automatyczne stanowią kluczowy element naszej pracy, można powiedzieć, że są naszym konikiem – specjalizujemy się w testach i jest to niewątpliwie nasz wyróżnik na tle konkurencji.
Kiedy mówi się o testach UI na Androidzie, często pada nazwa Appium – być może o Appium słyszeliście wszyscy, być może tylko niektórzy z Was, a inni w ogóle. Niemniej jednak W Finanteq (w niektórych projektach) także wykorzystujemy Appium, jednak dzisiaj chciałbym skupić się na innym podejściu.
W Finanteq postanowiliśmy stawiać na bardziej natywne rozwiązania. W przypadku Androida jest to framework Espresso, a dla iOS framework XCTest.
Pierwsze kroki w kierunku rozwoju automatyzacji testów zaczęliśmy stawiać około 2015 roku. Wtedy to nasz CTO wpadł na pomysł automatyzacji testów regresyjnych, aby w większym stopniu opierać się na automatach. Pracowałem wtedy nad specyficznym projektem z dużą liczbą testów jednostkowych (dla zobrazowania skali – mówimy tu o tysiącach testów). Wówczas wydawało się to wystarczające, ale szybko się okazało, że potrzebujemy czegoś więcej.
Wtedy zaczęliśmy także pisać testy funkcjonalne oraz trochę testów Appium, tych UI, jednak szybko zrozumieliśmy, że to podejście nie jest opłacalne (przynajmniej w naszym przypadku).
Dlaczego? Koszt napisania testu UI, który przechodzi przez ekran i tak naprawdę sprawdza warstwę pośrednią – czy to jest jakiś View model, czy presenter, był praktycznie taki sam jak test przechodzący przez warstwę UI. Zaczęliśmy więc bardziej koncentrować się na na tych drugich.
Na początku nasz postęp był powolny. W 2015 roku, na starszych wersjach Androida (tj. 5, 6 albo już 7), osiągnęliśmy około 600 testów w ciągu półtora roku, dwóch lat ze średnio dwuosobowym zespołem. Kolejny projekt przyniósł lepsze wyniki, ale prawdziwy przełom nastąpił w 2020 roku, kiedy napisaliśmy aż 2 000 testów w ciągu roku. Testów, które się uruchamiają, bo czasem się pisze szablony (opowiem o tym później).
 Obecnie, w projekcie związanym z bankowością na Bliskim Wschodzie, mamy 2800 testów w ciągu 20 miesięcy, co przekłada się na 2300 zaimplementowanych kroków (o czym jeszcze później wspomnę), z pokryciem kodu na poziomie 92%, przy czym tak naprawdę pozostałe 8% to jest niedoskonałość samego mierzenia kodu. Wynika to głównie z ograniczeń narzędzia, którego używamy – JaCoCo, które bardziej zoptymalizowane jest pod Javę niż pod Kotlin. Nasz projekt jest oparty na Kotlinie (Pure Kotlin) i korzysta z Compose, co także wprowadza pewne wyzwania związane z mierzeniem pokrycia kodu.
Obecnie, w projekcie związanym z bankowością na Bliskim Wschodzie, mamy 2800 testów w ciągu 20 miesięcy, co przekłada się na 2300 zaimplementowanych kroków (o czym jeszcze później wspomnę), z pokryciem kodu na poziomie 92%, przy czym tak naprawdę pozostałe 8% to jest niedoskonałość samego mierzenia kodu. Wynika to głównie z ograniczeń narzędzia, którego używamy – JaCoCo, które bardziej zoptymalizowane jest pod Javę niż pod Kotlin. Nasz projekt jest oparty na Kotlinie (Pure Kotlin) i korzysta z Compose, co także wprowadza pewne wyzwania związane z mierzeniem pokrycia kodu.
Stack technologiczny

Jeśli chodzi o narzędzia, których używamy, to korzystamy z Cucumbera na Androida (Cucumber-Android), czyli nowej Open Source’owej wersji Cucumbera. Cucumber jest to bardzo użyteczne narzędzie do pisania i uruchamiania testów BDD mające implementację na większość platform i języków.
Następnie Espresso, oraz Compose UI Test, który de facto oparty jest na Espresso, ale jest głównie do Compose.
Dodatkowo używamy Spoona do uruchamiania testów, co pozwala na sharding testów, czyli wygenerowanie bardzo przyjemnych raportów oraz podglądanie logów z każdego testu. W naszym wypadku to narzędzie bardzo dobrze się sprawdza.
Poniżej przykładowy raport.
 Można kliknąć w dowolnym miejscu na takim pasku, łatwo wejść i zobaczyć, że test się nie udał, ponieważ zaznaczony jest na czerwono – także widać, w którym miejscu jest coś nie tak.
Można kliknąć w dowolnym miejscu na takim pasku, łatwo wejść i zobaczyć, że test się nie udał, ponieważ zaznaczony jest na czerwono – także widać, w którym miejscu jest coś nie tak.
Niektóre testy są na szaro – są to testy ignorowane z jakiegoś powodu. Na przykład testy, które uruchamiają się tylko na Androidzie 12 a akurat wpadły na Androida 10, więc są ignorowane. Nie uruchamiały się.
Podsumowując – tak wygląda raport Spoona. Powyższy przykładowy raport pokazuje 2727 testów wykonanych w 15 minut, na 24 urządzeniach (obecnie to już 25 urządzeń). Jest to czas wykonania wszystkich testów, jak i czas instalacji, który też wcale nie jest taki krótki.
Poniżej przykładowe porównanie:

One Plusie 7 pro – 115 testów, 5 minut (czasem krócej). Tak naprawdę to zależy też od tego, w jaki sposób testy się rozłożą.
Ulefone Note 13P – najsłabszy model z tym samym Androidem, ale nie polecamy tych telefonów. Na testy automatyczne nie do końca się nadają – są po prostu zbyt wolne.
Ogólnie, dobrze jest mieć telefony w miarę z szybkimi procesorami. Wtedy różnica jest diametralna.
Ciekawostka: w Appium podobny scenariusz uruchamia się około 1 minuty, tutaj mamy 2/3 sekundy.
Dlaczego wybraliśmy Cucumber?
Z kilku powodów. Na początku szukaliśmy technologii zapisu wymagań w sposób bardziej biznesowy. Były różne propozycje, ale wybór padł na Cucumber ze względu na jego dostępność na wiele platform oraz integrację na Androidzie oraz serwerze. Natomiast tej integracji nie było na iOS, ale z tym sobie poradziliśmy.
Więc tak naprawdę, bez względu na technologię, w jakiej piszemy aplikacje, to możliwa jest integracja Cucumbera.
Biznesowy język (w miarę możliwości 😊) – oczywiście do pewnego stopnia.
Scenariusze mogą być pisane przez nie-developerów (do pewnego stopnia 😊) – czyli m.in. przez analityków, dzięki temu że powstają jako zwykły tekst, a nie w Javie, czy Kotlinie.
Współdzielenie scenariuszy między środowiskami Android i iOS – Dla nas jest to „killer feature” tego narzędzia. Scenariusze piszemy raz i współdzielimy je między platformami, co pozwala na eliminację różnic w działaniu aplikacji na obu platformach. W momencie, gdy napiszę jakąś zmianę lub nowy scenariusz, jest to widoczne na iOS, w związku z czym naprawdę wyeliminowaliśmy różnice funkcjonalne. Jeśli jakieś różnice się pojawią to jest to już kwestia interpretacyjna, która zawsze się może zdarzyć. Natomiast z naszego doświadczenia wynika, że przy takiej skali w projekcie, w którym jestem (gdzie jest około 300 ekranów), to gdy nie ma takiego scenariusza, to zazwyczaj działa źle i inaczej na innej platformie. Dlatego bardzo ważne jest by tworzyć dokładne scenariusze i je sobie współdzielić.
Dobrze się skaluje, raz zdefiniowane kroki są używane wielokrotnie i nie wymagają ponownej implementacji – Cucumber pozwala również na skalowanie testów, ponieważ kroki testowe mogą być wielokrotnie wykorzystywane. Na przykład, na 2 800 scenariuszy mamy tylko 2 300 kroków, co oznacza, że możemy dodawać nowe scenariusze bez konieczności implementowania nowych kroków.
Odporny na refaktor kodu – tak napisane scenariusze tak naprawdę są kompletnie niezależne od architektury aplikacji, czy użytych technologii. W ubiegłym roku gładko przeszliśmy z View do Compose. Nieważne, czy przeszliśmy z MVP do MVVM, tak naprawdę mieszamy sobie różne architektury i po prostu z punktu widzenia testów nie ma to znaczenia. Można robić dowolny refaktor, można przepisać sobie całą logikę biznesową ale zachowując funkcjonalność od strony użytkownika, puścić testy i sprawdzić, że wszystko działa. Nie ma takiego problemu, że testy też trzeba zmieniać, bo zmieniliśmy coś w kodzie, bo zrobiliśmy jakiś refaktor.
Architektura
Warto zaznaczyć, że testy uruchamiamy na fizycznych urządzeniach. Mamy swoją farmę, z ponad trzydziestoma telefonami, obejmującymi wersje Androida od 6 do 13. W projekcie, gdzie jest bardzo dużo testów, starsze wersje urządzeń są pomijane ponieważ są za wolne i potrafią się zawiesić. Uruchomienie na nich dziennie tysięcy testów sprawia, że się zacinają.
Minimalna wersja Androida, na którą warto zwrócić uwagę przy tej skali testów, to Android 8.
Poniżej widzicie schemat farmy urządzeń. Stworzyliśmy nasz własny serwer, który można nazwać serwerem telefonów, który zarządza farmą. Mamy ponadto Jenkinsa oraz kilka nodów Jenkinsa – obecnie jest ich siedem. W momencie budowania każdy z tych nodów odpytuje serwer w poszukiwaniu adresów IP dostępnych telefonów. Warto dodać, że telefony mają włączone debugowanie USB.
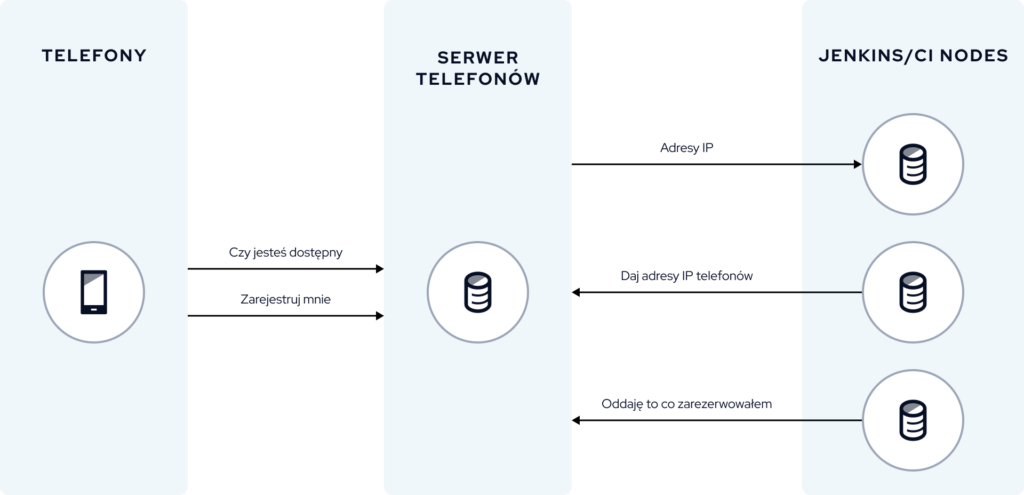
Nasz serwer komunikuje się z telefonami. Innymi słowy, telefony rejestrują się na serwerze. To jedna kwestia. Dodatkowo, przy każdym zapytaniu od node, serwer sprawdza, czy telefony są nadal dostępne, ponieważ czasami zdarza się, że telefony potrafią się odpiąć. Pojawiają się różne problemy. Dlatego serwer zbiera listę dostępnych telefonów, ich adresy IP w sieci, a następnie zwraca te informacje do node.
W tym momencie każdy node nawiązuje połączenie ADB po IP z każdym z telefonów. Dzięki temu maszyna Jenkinsa jest praktycznie połączona z każdym z telefonów, jakby była fizycznie podłączona przez kabel. A jak jest połączona? Powiedzmy z dwudziestoma, czy trzydziestoma telefonami?
Cała ta infrastruktura działa w dedykowanej sieci, która nie ma dostępu do Internetu. Dostęp do tej sieci mają tylko trzy grupy komponentów (serwer urządzeń, nody CI/Jenkinsa, farma telefonów) oraz developerzy, którzy mogą zdalnie połączyć się z dowolnym telefonem i przeprowadzić potrzebną operację.
Warto wspomnieć, że większość z nas pracuje zdalnie, dlatego też możliwość zdalnego logowania się do tych telefonów jest bardzo istotna. Po zakończonym buildzie nody robią release telefonu.
Aplikacja na testowym telefonie oraz zestawienie wykorzystywanych urządzeń
Poniżej screen, jak wygląda aplikacja, którą musieliśmy napisać i zainstalować na tych telefonach.
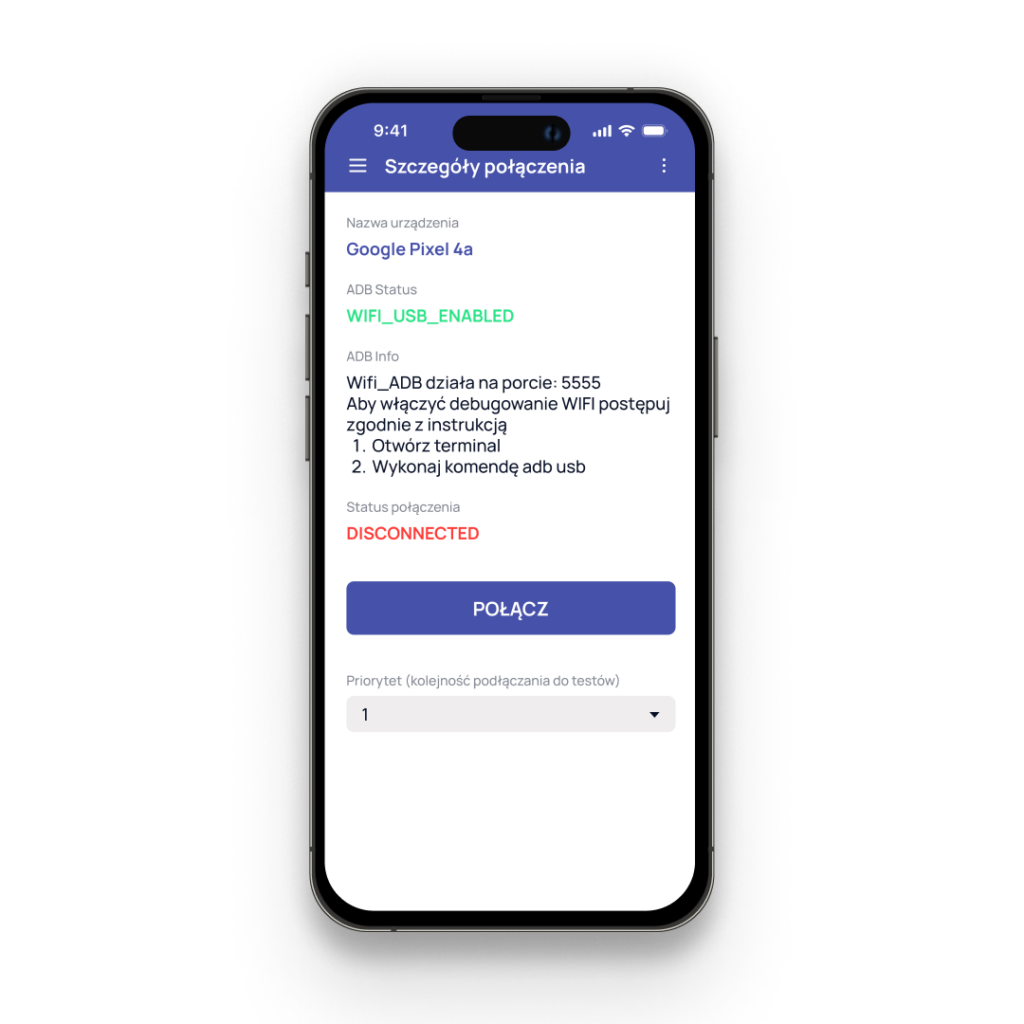 Jeśli debugowanie WiFi nie jest włączone, to aplikacja wyświetla instrukcję jak je włączyć. Tutaj na przykładzie Pixela 4a. Dzięki tej aplikacji możemy połączyć urządzenie, czyli zarejestrować się na serwerze, tak, żeby było dostępne do testów lub je odłączyć. Dodatkowo możemy ustawić priorytet, czyli określić, jak ma się pokazać na liście, która jest tutaj, czyli czy ma być wyżej, czy niżej.
Jeśli debugowanie WiFi nie jest włączone, to aplikacja wyświetla instrukcję jak je włączyć. Tutaj na przykładzie Pixela 4a. Dzięki tej aplikacji możemy połączyć urządzenie, czyli zarejestrować się na serwerze, tak, żeby było dostępne do testów lub je odłączyć. Dodatkowo możemy ustawić priorytet, czyli określić, jak ma się pokazać na liście, która jest tutaj, czyli czy ma być wyżej, czy niżej.
Na poniższej liście pokazana jest tylko część urządzeń – ponieważ, jak już wspomniałem, mamy ich ponad trzydzieści. To zbyt duża liczba na jeden ekran. Poza tym mamy prostą stronę internetową, na której zarządzamy tymi urządzeniami.
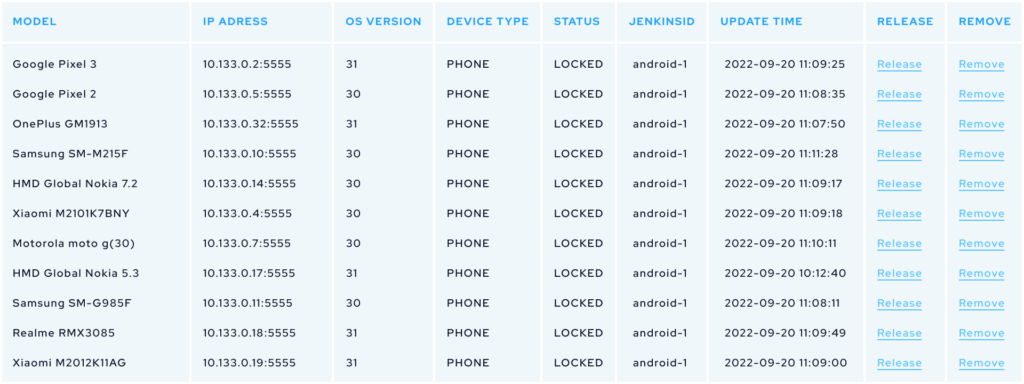
Możemy na niej sprawdzić takie informacje jak: modele telefonów, ich nazwy, w przypadku starszych wersji numery seryjne, wersje systemu Android, IP, wersje API, typ urządzenia (ponieważ w przeszłości mieliśmy także tablety, ale obecnie są to tylko telefony), aktualny status, czyli czy urządzenie jest zarezerwowane, node jaki aktualnie używa tego urządzenia, a także datę ostatniego dostępu.
Możemy również usunąć urządzenie, zarówno z poziomu aplikacji, jak i tej strony i zwolnić je w przypadku ewentualnych błędów. Warto zaznaczyć, że to się zdarza rzadko – urządzenia zazwyczaj poprawnie są zwalniane po zakończonych operacjach.
Konfiguracja per projekt
Możemy określić minimalną i maksymalną liczbę urządzeń. W przeszłości tego nie robiliśmy, ale teraz, przy naszej skali, gdzie mamy praktycznie tyle samo testów w dwóch projektach, tj. po około 2 800 testów, zdecydowaliśmy się na wprowadzenie minimalnej liczby urządzeń, tak żeby build się nie zaczął, jeśli taka liczba nie jest dostępna.
Mamy również możliwość określenia minimalnej wersji systemu Android, która nas interesuje, oraz pominięcia konkretnych modeli telefonów. Choć zdarza się to rzadko, czasem jest tak, że pewne funkcje działają na niektórych telefonach tylko w jednym projekcie lub w ogóle nie działają, więc te telefony są pomijane. Były również przypadki, gdzie niektóre telefony zawieszały się. Przykładem są Nexusy 5X i 6P, które miały takie samo oprogramowanie, ale zawieszały się w niektórych scenariuszach, podczas gdy inne telefony z tą samą wersją Androida działały poprawnie.
Ostatnią rzeczą, którą możemy skonfigurować to wybór konkretnego telefonu i właśnie na nim uruchomić testy.
Problemy
W ogólnym rozrachunku całość działa dobrze, ale pojawia się pewne problemy.
Pierwszym z nich są puchnące baterie. Telefony są ciągle podłączone do ładowania, ponieważ przez cały czas muszą mieć włączony ekran przez. Aby to osiągnąć, musimy w ustawieniach telefonu wybrać opcję „Nie wyłączaj ekranu, jeśli podłączony” i utrzymywać stałe podłączenie urządzeń do ładowarki. Podatne na puchnięcie są przede wszystkim telefony, które nie mają mechanizmów ochrony baterii. Mimo, że telefony te działają, wyglądają jak kanapka. Na szczęście większość telefonów ma zabezpieczenie maksymalnego ładowania do 80% i tutaj problem z reguły nie występuje.
Czy kiedyś jakiś telefon wybuchł?
Na szczęście jeszcze nie doszło do takiego ekstremalnego przypadku, żeby bateria wybuchła. Chociaż gdybyśmy zbyt długo odkładali wymianę baterii, mógłby to być potencjalny scenariusz.
W praktyce, kiedy bateria zaczyna puchnąć, wysyłamy ją do serwisu w celu wymiany – zdarza się raz w roku. I do tej pory nikomu nie zdarzyło się sprawdzić, czy bateria rzeczywiście mogłaby wybuchnąć.
Kolejny problem to wyłączające się ekrany. Chociaż mamy ustawione, żeby ekran się nie wyłączał, czasami telefon gubi połączenie z kablem. Telefony nie są projektowane do takiego użycia, dlatego mogą pojawiać się różne problemy. To jest ogromne obciążenie dla telefonów. W trakcie dnia uruchamianych jest kilkadziesiąt tysięcy testów, czasem dochodzi do 20 buildów.
Codziennie na tę farmę jest więc zrzucane te kilkadziesiąt tysięcy testów. Tak jak wspominałem, jest to duże obciążenie i różne rzeczy potrafią się dziać – np. właśnie raz w miesiącu może się w jakimś urządzeniu wyłączyć ekran i generalnie popsuć cały build.
Odłączenie od sieci WiFi. Ten problem występuje bardzo rzadko, ale ponieważ jest to urządzenie fizyczne, więc może wystąpić. System jest tak inteligentny, że szuka sieci, które mają dostęp do internetu. A jak jakaś nie ma, to uważa ją za złą, więc potrafi odłączyć od niej urządzenie – przy czym tutaj również zaznaczamy, żeby system nie odłączał jej i to z reguły działa. Są jednak takie sytuacje jak np. restart anteny i urządzenia ponownie nie podłączają się do sieci. Trzeba to wtedy zrobić ręcznie.
Utrata połączenia ADB. To również zdarza się sporadycznie. Z reguły jest tak, niby jest z nimi połączenie, ale w wywołanie jakiejkolwiek komendy ADB nie działa. Po prostu zawiesza się. Zazwyczaj pomaga restart, czy update oprogramowania – często po sprawdzeniu urządzenia okazuje się, że jest aktualizacja systemu.
W związku z tym trzeba po prostu wcześniej zrestartować telefony oraz od czasu do czasu wyłączać i włączać, aktualizować wszystkie aplikacje, w tym usługi Google oraz system.
Spowolnienie systemu. Widać to w szczególności na telefonie Ulephone, gdzie testy wyraźnie powodują spadki wydajności. W miarę narastającego obciążenia telefony stają się coraz wolniejsze. Chociaż niektóre modele, np. One Plus, radzą sobie dobrze. Samsungi są pod tym względem gorsze – problemów z wydajnością po pewnym czasie użytkowania doświadczają nawet zwykli użytkownicy. Niektóre telefony z kolei w ogóle nie pozwalają na uruchamianie testów zdalnie. Tak mieliśmy z takimi markami jak Huawei, czy TCL, które kupiliśmy, by w swojej farmie mieć wiele różnych urządzeń. Inne marki, które posiadamy to Samsungi, Pixele, HTC, OPPO i wiele innych – w zasadzie ciężko wymienić taką, której nie mamy.
Wrócę jeszcze raz do telefonu TCL, który kupiliśmy w celu weryfikacji jego działania. Tutaj uruchomienie testów przez WiFi okazało się niemożliwe. Podobnie było w przypadku Huawei: mamy jeden model, na którym wszystko działa, ale na większości nie działa. Ciekawym zjawiskiem jest fakt, że podłączenie lub odłączenie kabla może wywołać rozpoczęcie testów. To znaczy, startuje testy przez ADB, ale nic się nie dzieje przez powiedzmy godzinę. Podłączamy do ładowarki i nagle testy startują. Dlatego zdecydowaliśmy się zrezygnować z testów na urządzeniach Huawei.
Przesyłanie plików APK przez WiFi jest wolne. Jest tak, ponieważ cała komunikacja odbywa się przez WiFi. Zacznijmy od tego, że aplikacja, nad którą pracujemy zajmuje 80 MB w wersji debug. Do tego dochodzi około 30 MB aplikacji testującej, tzn. jak piszemy testy androidowe instrumentacyjne to dochodzi tak jakby drugie APK, które zawiera te testy. Przesyłanie plików o rozmiarze ponad 100 MB do 25 telefonów naraz jest czasochłonne. W przypadku przesyłania i zainstalowania do pojedynczego urządzenia zajmuje to mniej niż 10 sekund, ale w przypadku przesyłania do wielu urządzeń naraz, czas ten znacząco się wydłuża, czasami dochodząc do 3 minut właśnie w tym konkretnym projekcie. Następnie przez około 10 – 12 minut trwają testy. To jest kolejna rzecz, nad której optymalizacją będziemy pracować. Tego nie można tak łatwo skalować. A dokupienie 100 nowych urządzeń nie przyniesie oczekiwanych efektów, bo to nie działa w taki sposób.
Poza architekturą hardware’owo-serwerową, wprowadziliśmy zmiany dosłownie wszędzie, gdzie się dało, żeby wszystko działało w oczekiwany sposób. Teraz przejdę do zmian w Spoonie.
Zmiany w Spoonie
Narzędzie to nie jest rozwijane, więc tak naprawdę mamy swojego forka, nad którego rozwojem pracujemy.
Najpierw instalacja na wszystkich telefonach – gdy wystąpi błąd testy nie są uruchamiane na tym telefonie.
Pierwsza rzecz: stabilność. Mam tutaj na myśli sytuacje, w których np. testy na jednym z urządzeń z jakiegoś powodu się nie zainstalowały – mógł to być problem ADB. W starszych urządzeniach problemem był brak miejsca, przez który psuł się cały build.
W związku z tym wprowadziłem taką zmianę, że testy uruchamiamy tylko na urządzeniach, na których faktycznie się zainstalowały. Obecnie schemat działania wygląda tak, że najpierw sprawdzamy, na których urządzeniach testy są zainstalowane, dopiero później je rozpoczynamy. Jest to drobna modyfikacja w Spoonie, który domyślnie działał nieco inaczej – powodował całkowity błąd buildu, ale dzięki niej unikamy tego problemu.
Dezinstalacja poprzedniej wersji w razie błędu instalacji. To druga kwestia, którą chciałbym omówić. Standardowo jak instalujemy nową wersję systemu, to w Android Studio pojawia się komunikat, że jest już taka wersja i czy chcesz ją odinstalować. Tutaj ma się to zadziać automatycznie, więc Spoon po prostu dostawał błąd instalacji, bo wersja już była. Teoretycznie po każdym buildzie aplikacje są odinstalowywane, ale zdarzało się w wyniku błędu, że odinstalowanie aplikacji nie wykonało się . Inna sytuacja, to gdy ktoś wziął takie urządzenie, wykonał na nim jakieś czynności i odłożył telefon do farmy, zostawiając swoją aplikację – wtedy również pojawiał się błąd, że nie da się zainstalować aplikacji, ponieważ już jest.
W związku z tym dodałem prosty workaround, który w razie błędu instalacji odinstalowuje wersję automatycznie. To także znacząco usprawniło, ustabilizowało build. Wyeliminowało te problemy, w których po prostu build się nie udawał, tylko dlatego, że nie mógł czegoś zainstalować.
Zmiany w Cucumber
Jeśli chodzi o samego Cucumbera, to pierwszą rzecz, którą trzeba było zoptymalizować to jego corowy mechanizm.
Optymalizacja mechanizmu dopasowywania kroków Gherkin<->Java/Kotlin. Cucumber jest oparty na refleksji, czyli przykładowo stworzymy krok, tj. napiszemy zdanie typu: „Zakładając, że xyz”, to on matchuje to z implementacją w Kotlinie, czy w Javie. I to się dzieje przy użyciu wyrażeń regularnych, i to na starszych telefonach.
Warto wspomnieć, że zaczynaliśmy od Androida 6. Przy rosnącej liczbie testów, to stawało się coraz wolniejsze, bo za każdym razem należało przeszukać coraz więcej rzeczy. Jest to pierwsza rzecz, którą zoptymalizowaliśmy, wprowadzając prosty cache – jako pull request do corowej wersji Cucumbera.
Obsługa Jetpack Compose. Drugą rzecz, którą dodaliśmy, jest obsługa JetPacka Compose – to była konieczność. Wymagało to dodania obsługi Junit Rules do Cucumber Android.
FTQ Espresso Toolkit
Najważniejszą rzeczą, żeby pisać testy na dużą skalę jest posiadanie odpowiednich narzędzi. Dlatego też w Finanteq stworzyliśmy własny Espresso Toolkit.
 Mamy espresso, podstawowe API. Jednak problem polega na tym, że to się nie skaluje – konieczne jest wielokrotne powtarzanie tego samego, żeby zrobić prostą rzecz. Nawet jeśli zagłębilibyśmy się w dokumentację Espresso, żeby dowiedzieć się, jak wykonać jakieś działanie, trafiamy na bardzo długą listę kroków typu: „kliknij tu, wykonaj to”, i tak dalej.
Mamy espresso, podstawowe API. Jednak problem polega na tym, że to się nie skaluje – konieczne jest wielokrotne powtarzanie tego samego, żeby zrobić prostą rzecz. Nawet jeśli zagłębilibyśmy się w dokumentację Espresso, żeby dowiedzieć się, jak wykonać jakieś działanie, trafiamy na bardzo długą listę kroków typu: „kliknij tu, wykonaj to”, i tak dalej.
Teraz wyobraź sobie, że musisz to robić kilkadziesiąt razy dziennie, pomnożone przez kilkanaście osób, a następnie przez kilkaset dni. Wtedy okazuje się, że ilość pracy jest ogromna, prawda? Nawet gdyby udało się zoptymalizować połowę z tych kliknięć, to już dużo.
Dlatego szybko przystąpiliśmy do tworzenia własnych narzędzi, które znacznie przyspieszyły naszą pracę.
Stworzyliśmy nasz własny zestaw narzędzi do testów, który liczy już 14 000 linii kodu, może nawet więcej niż samo Espresso oraz zawiera ponad 500 testów. Głównym celem było zoptymalizowanie działania Espresso, które na dużą skalę nie radziło sobie zbyt dobrze.
Poniżej znajdziesz listę naszych usprawnień i problemów, które rozwiązaliśmy:
Stabilizacja działania Espresso, automatyczny scroll ekranu. Na pierwszy rzut oka kwestia ta może wydawać się banalna, ale trzeba pamiętać, że na jednym telefonie coś będzie widoczne, a na innym trzeba będzie przeskrolować. Ogólnie rzecz biorąc, większość interfejsów jest przewijalna, niezależnie od tego, co dokładnie robimy. W związku z tym, w praktyce często konieczne jest przewijanie. Espresso niestety nie obsługuje tej funkcji automatycznie, więc musimy sami to stworzyć. To może wydawać się drobnostką, ale znacznie ułatwia pracę.
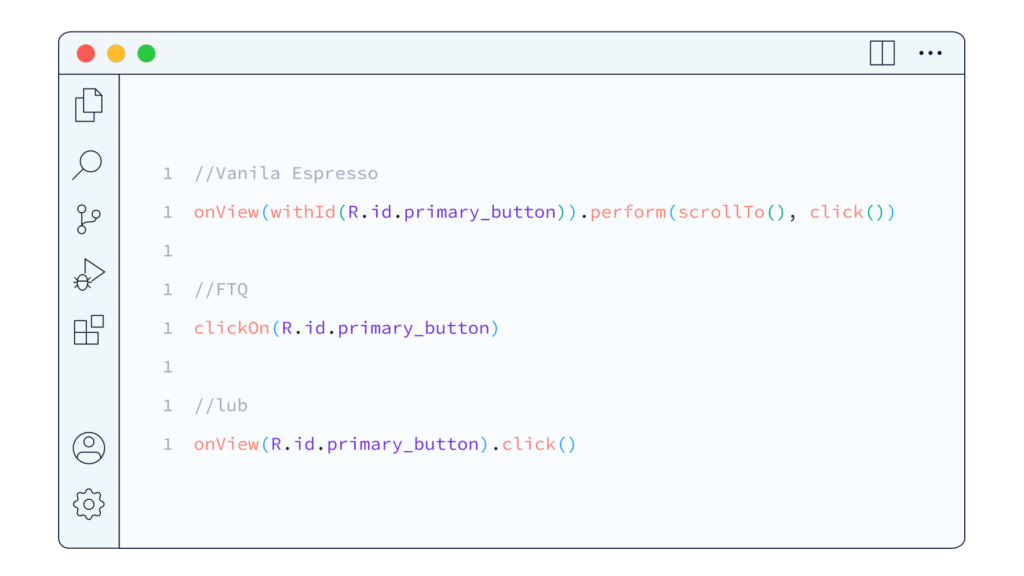 Jest to proste wywołanie. Jeśli cokolwiek można zoptymalizować, to w naszym wypadku sprowadza się to do wywołania jednej funkcji, gdzie przekazujemy tylko tekst na ekranie lub ID elementu, a w przypadku Compose jest to semantic tag.
Jest to proste wywołanie. Jeśli cokolwiek można zoptymalizować, to w naszym wypadku sprowadza się to do wywołania jednej funkcji, gdzie przekazujemy tylko tekst na ekranie lub ID elementu, a w przypadku Compose jest to semantic tag.
Problemy z klawiaturą, kliknięciami. Kolejnym wyzwaniem są problemy z obsługą klawiatury oraz kliknięciami, szczególnie na nowszych wersjach systemu Android. Często te kliknięcia są niestabilne i mogą nie działać poprawnie. Pamiętam, że gdy zaktualizowałem jeden z telefonów z Androida 9 na 10, połowa testów nagle przestała działać. Rejestrowane było co drugie kliknięcie. Klawiatura to de facto zewnętrzna aplikacja, a Espresso działa w oparciu o synchronizację z tym, co dzieje się w głównym wątku aplikacji. Jednak ta synchronizacja nie zawsze działa idealnie, i wystarczy, że nie zadziała raz, aby cały test nie zadziałał. Zdarza się, że raz na 2 000 testów cały build się nie udawał.
FTQ Compose Toolkit
FTQ Compose Toolkit to kolejna rzecz, którą musieliśmy napisać. Pomimo, że Compose UI Test od Google jest lepsze, bardziej przemyślane niż Espresso – jest czysto kotlinowe, to wciąż brakuje wielu funkcji.
Ponownie, jednym z brakujących elementów jest automatyczny scroll. To jest podstawowa funkcja, jeśli chcemy pisać testy UI. Musieliśmy więc sami dodać funkcję sprawdzania tekstu, mimo, że istnieje już taka funkcja – jednak u nas działa to w ten sposób, że w scenariuszach testowych zawsze sprawdzamy teksty za pomocą identyfikatorów. Testy te mogą być uruchamiane w różnych językach i powinny działać. Nie hardkodujemy ich wartości, tylko identyfikatory zasobów. Dlatego wszystkie metody, które piszemy w naszych narzędziach, automatycznie zamieniają identyfikator tekstu na jego wartość.
Testowanie LazyColumn/LazyRow. Ciężko mi było uwierzyć, że nie ma tego w Compose, bo w Espresso było. Było podstawowe API do testowania, tutaj nie ma, a jest to podstawowy komponent. Był to duży problem, ale udało się go rozwiązać łatwiej niż się spodziewałem. Jak?
Po prostu stworzyliśmy sobie API do testowania LazyColumn/LazyRow wykorzystując pewne mechanizmy działania tych komponentów.
Testowanie animacji Lottie. W naszej aplikacji mamy bardzo dużo animacji, więc jest to dla nas bardzo istotne, by sprawdzać, czy ustawiona jest odpowiednia animacja, czy działa w pętli, czy nie, czy już wystartowała. Zdarzały się przypadki, kiedy ktoś dokonał zmian w kodzie, a animacja przestawała działać poprawnie. Dlatego zawsze, gdy mamy ekran z animacją, przeprowadzamy testy, aby upewnić się, że animacja działa tak, jak powinna.
Mierzenie kodu. Niestety, nie możemy liczyć na Google. Jedynie fork JaCoCo poprawnie mierzy pokrycie kodu w Compose. Jest jeszcze narzędzie od JetBrains w IntelliJ, ale nie nadaje się do automatyzacji.
Wracając do JaCoCo – nie mierzy on poprawnie pokrycia kodu w Compose. Prosta funkcja w Compose generuje bardzo dużo kodu, który z punktu widzenia JaCoCo powinien być przetestowany. Bardzo dużo if’ów, bardzo dużo instrukcji. I tak naprawdę mamy funkcję wyświetlającą tekst, a według JacoCo pokrycie kodu to 5% – pomimo tego, że tam nie ma nawet jednego if’a. A wszystko się wyświetla i było sprawdzone, że się wyświetla.
W związku z tym musiałam stworzyć forka JaCoCo, który naprawia ten problem czyli de facto ignoruje nadmiarowe instrukcje kompilatora Compose.
Mockowanie danych. To przedostatnia rzecz którą trzeba było zrobić. Skoro testy działają, to są zamknięte – nie ma połączenia z serwerami, z niczym. Dane trzeba więc w jakiś sposób mockować. Żeby to zrobić efektywnie, szybko i na dużą skalę, wykorzystaliśmy bibliotekę, która w warstwie OkHttp rejestruje interceptora i zwraca gotowe dane. Więcej tutaj.
Problem z tą biblioteką był jednak taki, że musielibyśmy się bawić w tworzenie Jsonów, czy przygotowywanie niskopoziomowych danych.
Dlatego też stworzyliśmy nakładkę, która nieco bardziej wysokopoziomowo to mockuje. Tutaj mamy tak naprawdę wygenerowany swój enhancement do generatora OPEN API, który generuje endpointy w postaci stałych, których możemy używać w testach. Możemy po prosu napisać, że jakiś GET na jakiś endpoint ma zwróć mi taką odpowiedź i tą odpowiedzią jest już kotlinowa klasa, która jest generowana.
onGetRequest(Endpoints.someEndpointUrlGenerated())
.setResponse(SomeResponse(…))
To wygląda tak, jakbym wysokopoziomowo sobie to mockował.
Pod spodem, to się gdzieś parsuje do Jsona i ustawia w interceptorze OkHttp. Jest to dosyć szybkie i nie wymaga bawienia się w jakieś niskopoziomowe tematy.
FTQ Cucumber for Kotlin IntelliJ/Android Studio plugin
Ostatnie z narzędzi, które musieliśmy przygotować, żeby usprawnić swoją pracę, to wtyczka do IntelliJ i Android Studio (ponieważ nie ma oficjalnej wtyczki Cucumber dla Kotlina; jest dla Javy, Groovy, Scala; dodatkowa przeznaczona dla Javy w tamtym okresie nie radziła sobie zbyt dobrze, być może teraz działa lepiej).
Zdecydowaliśmy się więc na stworzenie wtyczki, która będzie pozwalać na nawigację pomiędzy implementacją a scenariuszem. Dodatkowo w trakcie użytkowania okazało się, że trzeba dorobić dodatkowe funkcjonalności, których nie było również w innych wtyczkach, takie jak:
- Generowanie sygnatury funkcji w kotlinie z wyrażeniem regularnym odpowiadającej krokowi w Gherkinie.
- Generowanie klas. Pisząc w Cucumberze w Gherkinie często się używa tabelek – te tabelki trzeba zmapować na kotlinowe klasy. Dlatego właśnie dodałem „Quick Actions”, żeby wszystko generowało się na podstawie tabeli – zaznaczam tabelkę i generuje się klasa pola (tj. kotlinowe Data Class).
- Możliwość uruchomienia scenariusza lub przykładu scenariusza na urządzeniu. W związku z tym, że Android Studio nie byłoby w stanie przekształcić scenariusza napisanego ludzkim językiem na konkretny test do uruchomienia, dlatego też konieczne było wygenerowanie odpowiedniej instrukcji z parametrami dla konkretnego scenariusza/przykładu tak aby 1 kliknięcie w edytorze uruchomić konkretny scenariusz
Wtyczka dostępna jest publicznie https://plugins.jetbrains.com/plugin/22107-cucumber-for-kotlin-and-android
Problemy
Niestabilne kliknięcia od Androida 10. To o czym już wspominałem, jest na to Issue, ma już ponad 3 lata, ale bodajże w wersji espresso 3.5 zostało to naprawione. Problem w tym że Espresso czy Compose Test są praktycznie nieaktualizowane. Google raz na rok wydaje lekki update, ale to zdecydowanie za mało.
My przez rok w zasadzie napisaliśmy bardzo dużo – już w samym Compose Test Toolkit zapewne tyle samo, co Google w swojej części. Jeśli używa się narzędzia na taką skalę, to postęp nie jest możliwy bez dodawania kolejnych usprawnień. Jeśli czegoś nie ma to nie ma. Tak jak w przypadku LazyColumn/LazyRow – oczywiście można założyć Issue, ale na realizację trzeba poczekać rok, albo i dwa. A przecież w tym czasie trzeba działać i dostarczać klientowi przetestowany kod.
Klawiatura. To jest problem na przykład chociażby z tego powodu, że kliknięcia w Espresso są dwuetapowe: najpierw oblicza się koordynaty elementu, gdzie trzeba kliknąć, a potem wysyła się zdarzenie kliknięcia. I pomiędzy tymi dwiema operacjami klawiatura może sprawić, że interfejs przeskakuje. Może się tak zdarzyć, że zostaną obliczone nieco inne koordynaty niż za chwilę będą – tak jakby ten element zostanie przesunięty w górę i kliknięcie nie trafia tam, gdzie trzeba. Ten problem udało nam się wyeliminować praktycznie w 100 procentach.
Różnice w działaniu. W momencie, kiedy wychodzi nowy system (teraz Android 13), to niektóre rzeczy działają inaczej, czy przestają działać w ogóle. Ponieważ aplikacja zaczyna inaczej się zachowywać, to testy, które miały pewne założenia, przestają działać. Na przykład na wspomnianym Androidzie 13 trzeba zezwolić na powiadomienia. W tej sytuacji testy powiadomień na tej wersji systemu nagle przestały działać, ponieważ tego nie uwzględniliśmy. Dopiero po dodaniu akceptacji pozwolenia na powiadomienia do testów wszystko zaczęło działać prawidłowo.
Kolejne różnice to te w działaniu klawiatury.
Na starszych Androidach system zazwyczaj automatycznie szukał pola tekstowego, żeby znaleźć focus i pokazać klawiaturę – począwszy od Androida 9, czy 10 tak się już nie dzieje. To również może powodować różnice w działaniu testów.
Animacje. Teoretycznie Google zaleca wyłączenie animacji, ale my postępujemy inaczej. Wszystkie nasze telefony mają ustawione w opcjach programistycznych animacje na 0.5, a domyślnie jest to 1. Z naszego doświadczenia wynika, że ustawienie na 0.5 jest o wiele lepsze, ponieważ wtedy aplikacja zachowuje się bardziej naturalnie. Kiedy wyłączamy animacje, to nie jest naturalne działanie aplikacji, więc pewne rzeczy, gdy zostaną ponownie włączone, mogą działać, ale wcale nie muszą. Dlatego generalnie nie polecam wyłączania animacji. Oczywiście Google mówi co innego – wyłącz animacje, bo inaczej testy mogą nie działać. To trochę jak powiedzenie: „Nie wychodź z domu, bo coś ci się może stać”. Ale co, jeśli naprawdę musisz wyjść z domu czyli np. musisz przetestować animację?
Podsumowując, 0.5x jest najlepszym ustawieniem. Były nawet przypadki, kiedy na niektórych urządzeniach, na przykład Nexusie 7, przy wyłączonych animacjach test się zawieszał, więc w ogóle konieczne było, żeby te animacje były.
Ponadto testujemy animacje. Jeśli wyłączymy animacje, to sprawdzanie animacji Lottie przestaje działać. Animacje wprowadzają pewne asynchroniczności, co oznacza, że czasem działają, czasem nie. Czasami coś się wykonuje lub sprawdza za wcześnie, innym razem za późno. To może skutkować tym, że testy działają przez trzy tygodnie na pięciu różnych urządzeniach, a potem nagle na innym urządzeniu przestają działać.
Ukryte błędy. Jest ich mnóstwo. Android i wszystko co się z nim wiąże to prawdziwa kopalnia błędów, które często ujawniają się właśnie podczas testowania. W naszym przypadku, gdzie testy uruchamiają się bardzo szybko, tzn. scenariusze, które wykonujemy – wejście na ekran, kliknięcie, wprowadzenie tekstu, sprawdzenie – trwają zaledwie kilka sekund. To tempo jest nieosiągalne dla człowieka. Dlatego jeśli coś działa powoli, to działa, ale gdy wykonujemy te same czynności bardzo szybko, nagle okazuje się, że coś nie działa. To staje się oczywiste podczas testów, a ukrytych błędów jest naprawdę wiele. Sam założyłem ich chyba kilkadziesiąt, albo nawet więcej.
Dodatkowo, wszystko jest asynchroniczne – chociaż może wydawać się synchroniczne, bo działamy od góry do dołu. Jednak pod spodem wszystko działa asynchronicznie. Mam pewne doświadczenie w pisaniu testów serwerowych, backendowych i innych testów jednostkowych, gdzie wszystko dzieje się krok po kroku. Tutaj jest inaczej, ponieważ testy są wywoływane w osobnym wątku, podczas gdy aplikacja działa w wątku głównym. W samej aplikacji istnieje wiele wątków, takich jak komunikacja, różne wątki robocze i wiele innych, które działają równolegle.
Co więcej, system wprowadza swoje własne asynchroniczności. Na przykład, nawet wywołanie finish na Activity nie jest synchroniczne, ponieważ finish jakby deleguje to działanie do systemu, a system wywołuje pewien callback. Oczywiście to się może zadziać jedno po drugim, ale też może zdarzyć się jakieś 5 milisekundowe opóźnienie i to wystarczy, żeby Espresso wskoczyło w tę 5 milisekundową „dziurę” i by test się nie udał.
Takie sytuacje także się zdarzały. To jest ogromna asynchroniczność – z tego wynikają różne niuanse. Często to są błędy w kodzie. To znaczy, mamy asynchroniczny kod, który wydaje się działać poprawnie, ale jednak został źle napisany, więc w trakcie testów pojawiają się problemy, tak raz na 300 testów coś nie działa prawidłowo. Czasem błędy wynikają z niedoskonałości samego mechanizmu synchronizacji w Espresso. Innym razem problem może leżeć po prostu w metodach testujących, które piszemy sami lub korzystamy z tych dostarczonych przez Google, które są niedokładne.
Ostatni problem – niepełna izolacja testów. Teoretycznie izolację można osiągnąć uruchamiając testy przez orkiestrator. W Spoonie również da się to ustawić nieco inaczej.
W każdym razie każdy test jest uruchamiany na „czystej aplikacji”, ale to wszystko znacząco spowolniłoby działanie testów. Czyszczenie danych aplikacji, uruchamianie nowego procesu – to wszystko wymaga czasu. Nawet dodatkowe dwie sekundy na każdym z kilkuset testów na jednym urządzeniu mogą skumulować się do kilku lub nawet dziesięciu minut w przypadku dużej liczby testów. Przy takiej skali w jakiej działamy nie możemy sobie na to pozwolić.
Dlatego izolację zapewniamy w inny sposób, na przykład poprzez czyszczenie stanu. Jeśli korzystamy z Daggera, to po prostu czyścimy go, przywracając aplikację do stanu początkowego (tworząc nowy komponent daggerowy co powoduje stworzenie singletonów jeszcze raz). Monitor stosu aktywności pomaga nam w wyczyszczeniu wszystkich wystartowanych aktywności po zakończonym teście.
Inny problem to statyczne zmiany. Oczywiście, teoretycznie nikt nie programuje zmiennych statycznych. Ale czasem, z różnych powodów, takie zmienne się pojawiają, jakieś singletony, nawet nie nasze, ale w kodzie napisanym w Javie, czy w Kotlinie się pojawiają. Raz zainicjowane zmienne mogą trzymać dane w pamięci, a to może wprowadzać błędy w testach. Warto też zwracać uwagę na uprawnienia. Raz nadane uprawnienie nie może być usunięte w trakcie testów, więc jesteśmy zmuszeni do pracy z tymi samymi uprawnieniami za każdym razem.
Posiadamy specjalny mechanizm mockowania, który pozwala nam oszukać aplikację i powiedzieć jej, że system zwraca odpowiedzi, które sami kontrolujemy. Jednak fizycznie te uprawnienia nadal istnieją.
Kiedy uruchamiamy testy z poziomu Gradle, to wszystko jest w porządku. Jednak gdy używamy Android Studio, wszystkie uprawnienia są zaakceptowane automatycznie. Dlatego programista może napisać test, który działa w porządku na jego komputerze, ale na CI (Continuous Integration) może nagle pokazywać błędy. To się zdarza, zwłaszcza, gdy testy są uruchamiane w innej kolejności, a nie ma testu, który nadaje potrzebne uprawnienia przed innym testem. Takie sytuacje są dość częste i dlatego ważne jest dbanie o izolację testów i właściwe zarządzanie uprawnieniami.
Podsumowując, w Finanteq wiemy jak pisać testy automatyczne na dużą skalę. Szukasz firmy, gdzie będziesz mógł rozwijać się u boku ekspertów z branży? Sprawdź nasze oferty pracy.