

W tym artykule pokażę jak współdzielić dane między wątkami oraz jakie są konsekwencje współdzielenia danych. Jest to piąty artykuł z serii o wielowątkowości w Java, jeśli dopiero zaczynasz przygodę z wątkami to zacznij od pierwszego artykułu.
Przykłady z tego artykułu są dostępne na GitHubie.
Przekazywanie danych do wątku
Mechanizm przekazania danych do nowego wątku wykorzystaliśmy w poprzednim artykule – w programie, który miał za zadanie obserwować pliki. Ten program tworzył dla każdego obserwowanego pliku nowy wątek. Główny wątek przekazywał do nowego wątku nazwę pliku i dlatego wątki wiedziały który plik mają obserwować.
Dla przypomnienia – nazwa pliku trafiała do nowego wątku w ten sposób:
- W głównym wątku pobieraliśmy nazwę pliku, zapisywaliśmy w zmiennej fileName, po czym przekazywaliśmy do konstruktora FileWatchThread.
String line = scanner.nextLine();
String fileName = line.substring("WATCH ".length());
Thread thread = new FileWatchThread(fileName);
- Nowa instancja FileWatchThread przechowywała tą zmienną w polu fileName.
class FileWatchThread extends Thread {
private final String fileName;
FileWatchThread(String fileName) {
this.fileName = fileName;
}
- Następnie uruchamialiśmy nowy wątek (metoda start()), który uruchamiał kod wewnątrz metody run(). W tej metodzie korzystaliśmy z pola fileName, czyli w efekcie ze zmiennej pochodzącej z głównego wątku.
class FileWatchThread extends Thread {
private final String fileName;
// ...
@Override
public void run() {
File file = new File(fileName);
// ...
Ze względu na to, że ta wartość przeszła przez kilka warstw, to dostrzeżenie przekazania wartości było lekko utrudnione.
Poniżej zobacz przykład programu, który również przekazuje Stringa do nowego wątku. W tym przykładzie tworzę nowy wątek wykorzystując zapis lambda, aby pokazać jak „wrzucam” zmienną do drugiego wątku.
import java.util.Scanner;
public class PassValueToAnotherThread {
public static void main(String[] args) {
var scanner = new Scanner(System.in);
System.out.println("Enter string to display in another thread:");
var string = scanner.nextLine(); // value created in main thread
var thread = new Thread(() -> {
System.out.println(string); // but used in a new thread
});
thread.start();
}
}
Ograniczenia współdzielenia danych
Spróbujmy zmodyfikować ten tekst w nowym wątku. Dopiszmy do niego prefiks „The string:”. Przykładowo jeśli użytkownik wprowadzi tekst „Lorem ipsum”, to wynikowym tekstem w zmiennej powinno być „The string: Lorem ipsum”.
import java.util.Scanner;
public class ModifyStringInThread {
public static void main(String[] args) {
var scanner = new Scanner(System.in);
System.out.println("Enter string to display in another thread:");
var string = scanner.nextLine();
var thread = new Thread(() -> {
string = "The string: " + string;
System.out.println(string);
});
thread.start();
}
}
Spróbuj uruchomić ten program. Nie uda się, bo kompilacja zakończy się poniższym błędem:
java: local variables referenced from a lambda expression must be final or effectively final
Ten błąd oznacza, że jeśli używamy jakiejś wartości w wyrażeniu lambda, to ta wartość powinna być zapisana w zmiennej final. Ewentualnie ta zmienna powinna być effectively final, czyli inaczej mówiąc, w praktyce powinna być final.
Zmienna jest effectively final, jeśli po jej zadeklarowaniu nigdy nie przypiszemy do niej ponownie wartości, a więc w praktyce wartość będzie niezmienna.
Skoro ta metoda nie zadziałała, to spróbujmy stworzyć dedykowaną klasę, która zmodyfikuje ten tekst.
import java.util.Scanner;
public class ModifyStringInThread {
public static void main(String[] args) throws InterruptedException {
var scanner = new Scanner(System.in);
System.out.println("Enter string to display in another thread:");
var string = scanner.nextLine();
var thread = new PrefixingThread(string);
thread.start();
thread.join();
System.out.println(string);
}
}
class PrefixingThread extends Thread {
private String string;
PrefixingThread(String string) {
this.string = string;
}
@Override
public void run() {
string = "The string: " + string;
System.out.println(string);
}
}
Gdy uruchomisz program i wpiszesz „Lorem ipsum”, to program wyświetli następujący tekst:
The string: Lorem ipsum
Lorem ipsum
Jak się okazało, ta metoda nie zadziałała tak jak chcieliśmy. Dzieje się tak dlatego, że:
- Java przekazuje parametry przez wartość. Zmienne typów złożonych przechowują wartości, które są referencjami do obiektu.
- W wątku głównym zapisaliśmy tekst w zmiennej string (a tak naprawdę referencję do stringa na stercie).
- Stworzyliśmy instancję PrefixingThread przekazując wartość zmiennej string.
- Konstruktor zapisuje wartość zmiennej string w polu string.
- Metoda run() w efekcie modyfikuje wartość pola string w instancji thread, a więc tak naprawdę nie współdzieli zmiennej pomiędzy wątkami, ale pracuje na danych przekazanych z głównego wątku.
Współdzielenie danych
Aby współdzielić dane pomiędzy wątkami powinniśmy cofnąć się do błędu kompilacji – podpowiada on jaki problem powinniśmy rozwiązać, aby współdzielić dane.
Zauważ, że gdy w Javie wywołujemy metodę (albo konstruktor), to przekazujemy wartość zmiennej. Tracimy możliwość zobaczenia zmian po powrocie z metody, do której „oddaliśmy” zmienną.
Jeżeli wartość umieścimy w polu jakiegoś obiektu, to wtedy zmienna z referencją do tego obiektu może być oznaczona final. Ta jedna referencja zostanie przekazana wszędzie, gdzie potrzebujemy tego obiektu. Dzięki temu współdzielimy jeden obiekt w wielu wątkach (bo referencja zawsze będzie wskazywała ten sam obiekt) i kilka wątków będzie w stanie „widzieć” zmiany tekstu.
import java.util.Scanner;
public class WrappedStringInThreads {
public static void main(String[] args) throws InterruptedException {
var scanner = new Scanner(System.in);
System.out.println("Enter string to display in another thread:");
var stringWrapper = new StringWrapper(scanner.nextLine());
var thread = new Thread(() -> {
stringWrapper.setString("The string: " + stringWrapper.getString());
System.out.println(stringWrapper.getString());
});
thread.start();
thread.join();
System.out.println(stringWrapper.getString());
}
}
class StringWrapper {
private String string;
public StringWrapper(String string) {
this.string = string;
}
public String getString() {
return string;
}
public void setString(String string) {
this.string = string;
}
}
W powyższym przykładzie zarówno główny wątek, jak i nowy wątek, posługują się jedną instancją StringWrapper. Zmienna stringWrapper jest „w praktyce final” (effectively final), bo nigdy nie przypisujemy do niej ponownie wartości.
Zmienia się tylko pole string w stringWrapper, ale wszystkie wątki posługują się tą samą instancją, więc „widzą” wszystkie zmiany.
Interferencja wątków
Współdzielone dane mogą być modyfikowane w każdym momencie, jeśli na to pozwolimy. Jeżeli dodatkowo weźmiemy pod uwagę to, że wątki mogą się „ścigać” i próbować modyfikować dane w tym samym czasie, to mogą pojawić się komplikacje. Wątki wtedy mogą sobie „przeszkadzać”, bo nie zwracają uwagi na to, co robią inne wątki. Nie zawsze wynik będzie taki, jak oczekujemy, a to dlatego, że wątki działają współbieżnie.
Czasami jeden wątek wpłynie na te same dane, których używa drugi, a czasami nie – dlatego rezultaty mogą być nieoczekiwane. Ze względu na niedeterministyczną naturę wątków, dostrzeżenie tego problemu może być utrudnione.
Spójrzmy na poniższy przykład:
public class MultithreadedCounterExample {
public static void main(String[] args) throws InterruptedException {
final var counter = new Counter();
var thread1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
counter.increment();
}
});
var thread2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
counter.increment();
}
});
var thread3 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
counter.increment();
}
});
thread1.start();
thread2.start();
thread3.start();
thread1.join();
thread2.join();
thread3.join();
System.out.println(counter.getValue());
}
}
class Counter {
private int value = 0;
public void increment() {
value += 1;
}
public int getValue() {
return value;
}
}
Moglibyśmy się spodziewać, że wynikiem uruchomienia tego programu będzie „3000”. Program uruchomi 3 wątki, każdy wątek ma pętlę, która 1000 razy zwiększy licznik o 1.
Spróbuj uruchomić ten program. U mnie za każdym razem jest inny wynik – w kolejnych uruchomieniach zobaczyłem: 2660, 2956, 2665, 3000, 2968, 1938.
Dlaczego tak się dzieje? Wątek główny czeka na zakończenie każdego z wątków (join()), więc mamy pewność, że wszystkie pętle zakończyły działanie. Metoda increment() ma bardzo prosty kod: value += 1. Skąd więc takie dziwne wyniki?
Rozkład na czynniki pierwsze
Przetestujmy uproszczony program.
public static void main(String[] args) {
final var counter = new Counter();
for (int i = 0; i < 3000; i++) {
counter.increment();
}
System.out.println(counter.getValue());
}
Ten program za każdym razem wyświetla poprawny wynik – 3000. Wygląda na to, że coś wpływa na poprawne zliczanie tylko w sytuacji, w której używamy wielu wątków.
Spróbujmy zbadać, co się dzieje w JVM, co może wpływać na działanie licznika. Spojrzymy na kod bajtowy, który został wygenerowany przez kompilator Javy. Użyję do tego narzędzia javap.
javap -c Counter.class
class com.finanteq.multithreading.interference.Counter {
com.finanteq.multithreading.interference.Counter();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: iconst_0
6: putfield #7 // Field value:I
9: return
public void increment();
Code:
0: aload_0
1: dup
2: getfield #7 // Field value:I
5: iconst_1
6: iadd
7: putfield #7 // Field value:I
10: return
public int getValue();
Code:
0: aload_0
1: getfield #7 // Field value:I
4: ireturn
}
Zbadajmy funkcję increment(). W oryginalnym kodzie ta funkcja miała jedną linijkę – po skompilowaniu, ma ona aż 10 instrukcji bajtowych. Kod value += 1 został rozbity na 4 instrukcje (od 2 do 7).
Według kodu bajtowego, JVM w ramach tej metody wykonuje następujące rzeczy:
- Pobranie pola value na stos wątku (getfield #7).
- Wrzucenie liczby 1 na stos (iconst_1).
- Dodanie ostatniej liczby ze stosu do zmiennej (iadd).
- Zapisanie ostatniego wyniku w polu value (putfield #7).
Jedna operacja w praktyce nie jest taka prosta, bo wymaga wykonania tych wszystkich 4 instrukcji, aby zaktualizować pole value.
Każdy wątek ma swój oddzielny stos. Gdy jeden wątek właśnie dodaje 1 do wartości na stosie, drugi może właśnie pobierać pole value na swój stos, nie czekając, aż pierwszy wątek zapisze wynik. Drugi wątek nie wie, że właśnie w tej chwili to pole jest aktualizowane i pracuje na nieaktualnej wartości pola value.
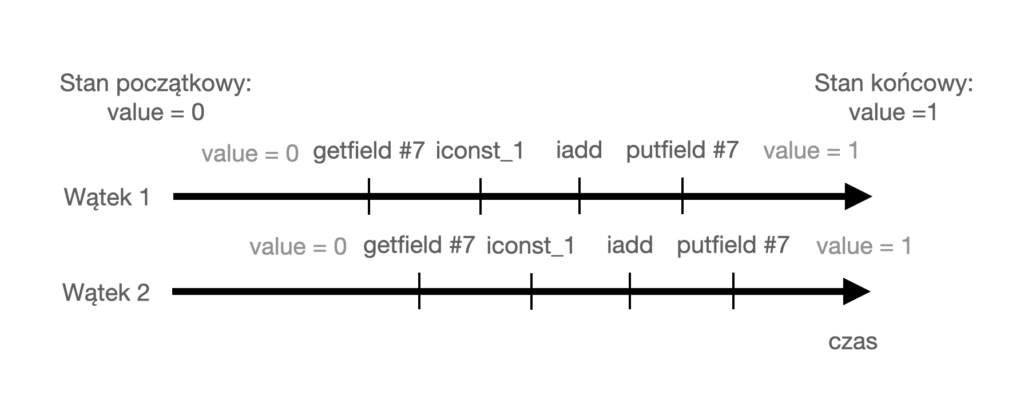
W powyższym przykładzie wątki teoretycznie wykonywały pracę tak jak powinny, ale ze względu na implementację dawały nieoczekiwane wyniki w niekontrolowany sposób. Taka sytuacja nazywa się wyścigiem (ang. race condition). Wątki „ścigają się”, aby wykonać swoje instrukcje, przez co dochodzi do niespójności w danych, z których korzystają. Jest to jeden z negatywnych efektów ubocznych tego jak wątki oddziałują na siebie (czyli interferują).
Wyścigi są trudne do badania, ponieważ są bardzo trudne do odtworzenia. Efekty uboczne zaobserwowane w danej chwili są wynikiem przypadku, więc próby powtórzenia błędu mogą przynieść inny skutek. Błąd może też nie występować przez większość czasu. Narzędzia takie jak debugger albo logger mogą minimalizować szansę na wystąpienie wyścigu, co jeszcze bardziej utrudnia naprawienie problematycznego kodu.
Synchronizacja wątków
W przypadku wyścigów, pomocny jest mechanizm synchronizacji. Synchronizacja ma na celu zapewnienie, że tylko jeden wątek wykonuje wskazany kod. Pozostałe wątki, które chcą wykonać synchronizowany kod, są dodawane do kolejki i czekają, aż zostaną „dopuszczone” do kodu.
Gdy wątek czeka, aż będzie mógł wykonać kod, to wtedy przechodzi w stan BLOCKED. O takim wątku mówimy, że jest zablokowany. W praktyce synchronizacja działa tak, że przepuszcza pierwszy wątek, który zacznie uruchamiać synchronizowany kod. Mechanizm blokuje pozostałe wątki do momentu, aż wątek skończy wykonywać ten kod. Wtedy blokada jest zwalniana i dopuszczany jest kolejny wątek z kolejki wątków.
Ten mechanizm działa podobnie jak mechanizm automatycznej bramki na parkingu zliczającej miejsca parkingowe. Taka bramka wpuszcza auta tylko jeśli jest miejsce na parkingu. Jeśli miejsc nie ma, to szlaban pozostaje zamknięty i kierowcy muszą czekać w kolejce. W przypadku synchronizowanego kodu będziemy mieli tylko jedno miejsce parkingowe, a wątki wchodzące do bloku kodu będą autami podjeżdżającymi do bramki.
Monitor służy do pilnowania tego, czy jakiś wątek został dopuszczony. Monitor to obiekt, który jest „punktem odniesienia” synchronizacji. Gdy jakiś wątek zostanie dopuszczony do synchronizowanego kodu, to monitor przechowuje informacje o blokadzie. Gdy jakiś inny wątek natrafi na kod „strzeżony” przez ten monitor, to zostanie zablokowany do czasu, aż blokada zostanie zdjęta.
W analogii z parkingiem, monitor będzie po prostu taką bramką. Zakładamy, że nasz parking zawsze może mieć tylko jedną bramkę (bo wątki możemy wpuszczać tylko pojedynczo).
Monitorem może być dowolny obiekt w Javie. Tak naprawdę może być nim nawet instancja klasy Object – nie musi to być specjalna klasa, bo monitor jest po prostu informacją dla maszyny wirtualnej Javy (JVM), w jaki sposób zarządzać blokadami wątków.
Synchronizowany blok kod zaznacza się słowem kluczowym synchronized, po którym w nawiasie podaje się właśnie monitor dla tego kodu.
var monitor = new Object();
synchronized (monitor) {
// synchronized code
}
Dobrze wykorzystany mechanizm synchronizacji pozwoli zapobiec wyścigom. Pamiętaj, że synchronizacja nie naprawia problemu i wyścigi mogą tak czy inaczej wystąpić. Natomiast nadmierna synchronizacja może sprawić, że wątki będą działały wolniej, bo będą musiały co chwilę czekać na zwolnienie blokad.
Monitory
Zazwyczaj do synchronizacji różnych bloków kodu używamy różnych monitorów. Dzięki temu zaznaczamy, że każdy blok powinien mieć oddzielną blokadę. To sprawia, że gdy jakiś wątek zablokuje jeden blok kodu, to wtedy nie blokuje innym wątkom możliwości uruchomienia innych synchronizowanych bloków. Tylko ten jeden blok kodu będzie zablokowany i blokada nie będzie miała wpływu na działanie innych bloków synchronized.
Jeden monitor możesz także wykorzystać do synchronizacji wielu bloków kodu – wtedy wszystkie bloki będą miały jedną blokadę. W takim wypadku, gdy wątek zablokuje dowolny blok, to zablokuje też wszystkie inne. Gdy monitor pilnuje wielu bloków kodu, to blokada na nich działa tak, jakby były jednym blokiem kodu. To znaczy jeden monitor = jedna wspólna blokada dla wszystkich bloków.
W analogii z parkingiem, taki monitor wykorzystany w kilku miejscach jest po prostu bramką dopuszczającą tylko jedno auto na cały plac. Niezależnie od tego, ile miejsca jest na placu, i gdzie kieruje się auto, pozostałe auta muszą zaczekać, aż plac będzie pusty. Tak samo tutaj – niezależnie od tego, który blok kodu chce wykonać wątek, wszystkie synchronizowane bloki współdzielą jeden monitor. Dlatego aby dopuścić więcej aut, musimy podzielić plac i postawić drugą bramkę.
import java.time.LocalDateTime;
import java.util.Random;
public class MultipleMonitors {
public static void main(String[] args) {
final var waiting = new SynchronizedWaiting();
var thread1 = new Thread(() -> {
waiting.waitFor(500);
System.out.println("Thread 1 finished at " + LocalDateTime.now());
});
var thread2 = new Thread(() -> {
waiting.doSomethingForOneSecond();
System.out.println("Thread 2 finished at " + LocalDateTime.now());
});
var thread3 = new Thread(() -> {
System.out.println("Random number: " + waiting.getRandomNumber());
System.out.println("Thread 3 finished at " + LocalDateTime.now());
});
thread1.start();
thread2.start();
thread3.start();
}
}
class SynchronizedWaiting {
private final Object waitMonitor = new Object();
private final Object otherMonitor = new Object();
private final Random random = new Random();
public void waitFor(int ms) {
synchronized (waitMonitor) {
sleep(ms);
}
}
public void doSomethingForOneSecond() {
synchronized (waitMonitor) {
// pretend we're working
sleep(1000);
}
}
public int getRandomNumber() {
synchronized (otherMonitor) {
// pretend we're rolling the dice for our random number
sleep(500);
return random.nextInt();
}
}
private void sleep(int ms) {
try {
Thread.sleep(ms);
} catch (InterruptedException e) {
// ignore, someone interrupted our sleep, I believe for a good cause
}
}
}
Random number: -482118840
Thread 3 finished at 2023-09-27T13:39:35.820764
Thread 1 finished at 2023-09-27T13:39:35.820766
Thread 2 finished at 2023-09-27T13:39:36.812447
Wątek Thread 3 i Thread 1 wykonują funkcję sleep(500), a jednak działały w tym samym czasie – dlatego też skończyły w podobnym czasie. Wygląda na to, że Thread 2 czekał jeszcze ok. sekundę po tym, jak Thread 1 skończył pracę.
W tym przykładzie metoda getRandomNumber() ma oddzielny monitor niż metody waitFor(int ms) oraz doSomethingForOneSecond().
Po uruchomieniu tego programu widzimy, że wątek Thread 3 nie blokuje pozostałych wątków. Użycie tego samego monitora w metodach waitFor(int ms) oraz doSomethingForOneSecond() sprawia, że te metody są w stanie zablokować się wzajemnie. Dlatego te metody wykonywane są jeden po drugim – gdy wątek Thread 1 kończy pracę, to zwalnia blokadę i dopiero wtedy pozwala kontynuować wątkowi Thread 2. Metoda getRandomNumber() ma natomiast niezależną blokadę i nie wpływa na pozostałe 2 wątki.
Poprawianie licznika
Wróćmy do wcześniej zidentyfikowanego problemu licznika – wątki podczas inkrementacji nie czekają, aż pozostałe wątki zapiszą swój wynik. Dlatego czasami pracują na nieaktualnych danych i wynik jest inny niż oczekujemy.
Z tego powodu wykorzystamy mechanizm synchronizacji do zablokowania innych wątków, aż aktualny wątek skończy inkrementację. Zaktualizujmy klasę Counter, aby posiadała ona monitor oraz blok synchronized.
class Counter {
private final Object monitor = new Object();
private int value = 0;
public void increment() {
synchronized (monitor) {
value += 1;
}
}
public int getValue() {
return value;
}
}
Spróbuj uruchomić ponownie zaktualizowany program. Teraz za każdym razem wynikiem będzie „3000”.
Zauważ, że w tej klasie mamy tylko jeden monitor. W tej sytuacji kod możemy trochę uprościć – jeżeli używamy tylko jednego monitora na obiekt, to jako monitor możemy wykorzystać this.
class Counter {
private int value = 0;
public void increment() {
synchronized (this) {
value += 1;
}
}
public int getValue() {
return value;
}
}
Ten program działa tak samo jak poprzedni – tylko tutaj naszym monitorem jest this, czyli obecna instancja Counter.
Jeżeli cała metoda wymaga synchronizacji (tak jak w tym przypadku) i monitorem jest this, to wtedy kod można jeszcze bardziej uprościć. W takim wypadku możemy oznaczyć całą metodę jako synchronized i zapis jest jeszcze krótszy.
class Counter {
private int value = 0;
public synchronized void increment() {
value += 1;
}
public int getValue() {
return value;
}
}
Operacje atomiczne
W języku Java są wyrażenia, które po skompilowaniu są tylko jedną instrukcją i z tego powodu mamy gwarancję, że podczas ich działania nie nastąpi wyścig. Takie wyrażenia nazywamy operacjami atomicznymi. Operacje atomiczne gwaranują, że podczas ich działania inny wątek nie wpłynie na wynik, ale nie zabezpieczą całego programu przed wyścigami.
Operacjami atomicznymi są następujące sytuacje:
- Czytanie zmiennej typu prostego (oprócz long i double)
- Zapisywanie zmiennej typu prostego (oprócz long i double)
- Czytanie pól oznaczonych volatile
- Zapisywanie pól oznaczonych volatile
Zmienne typu prostego o wielkości do 32 bitów (tj. byte, short, int, boolean, float) są na tyle małe, że procesor może wykonać odczyt i zapis w jednej instrukcji. Nowoczesne procesory obsługują odczyt i zapis danych do 64 bitów, a więc teoretycznie operacje na long i double też powinny być atomiczne na tych procesorach. Jednak bezpieczniej jest założyć, że praca na tych typach nie zawsze będzie atomiczna, bo nie mamy pewności, na jakim sprzęcie ktoś uruchomi nasz program.
Słowo kluczowe volatile
Odczyt i zapis pól jest trochę bardziej problematyczny. W Javie, gdy tworzymy nową instancję obiektu, JVM tworzy ten obiekt na stercie, a w zmiennej przechowuje adres instancji. Adres instancji znajdującej się na stercie nazywamy referencją. Zapisywanie referencji w zmiennej jest zawsze atomiczne, tzn. mamy gwarancję, że ta referencja nigdy nie będzie błędnym, częściowo zapisanym adresem.
Odczyt referencji też jest atomiczny (tzn. zawsze odczytana referencja będzie poprawnym adresem), ale nie zawsze mamy gwarancję, że to będzie najnowsza referencja. Czasami JVM zapamiętuje referencję (zapisuje w cache wątku) i nie za każdym razem pobierze aktualną referencję z pola, a odwoła się do zapamiętanej wartości. Jest to stary mechanizm JVM do optymalizacji programów.
Słowo kluczowe volatile służy do oznaczenia pól, które będą odczytywane i aktualizowane przez wiele wątków. To słowo kluczowe wyłącza mechanizm zapisywania referencji w cache. Volatile gwarantuje, że wszystkie wątki będą widziały aktualny stan pola. Jeżeli jakieś pole jest final, to nie ma sensu go oznaczać jako volatile. Wartość pola final nie może się zmienić, więc volatile nie zmienia sposobu działania programu.
Co dalej?
W kolejnych artykułach z cyklu pokażę wbudowane w Javę klasy, które ułatwiają pracę z danymi przechowywanymi w wielu wątkach. Zaprezentuję przykłady użycia, a w kolejnych artykułach zajmę się zaawansowanymi metodami blokowania wątków.
Następny artykuł: Wielowątkowość w Java – podstawowe kolekcje